
Making parallelism explicit with SoC-C
![]() Last week’s S-REPLS
keynote by Sylvan
Clebsch was a talk
about the limitations of current microprocessor architecture and how it hides
everything of interest from the programmer: instruction level parallelism is
hidden behind out-of-order execution, message passing is hidden behind cache
coherency, etc. This reminded me that I have been meaning to write about the
SoC-C project that aimed to make parallelism
explicit by adding some language extensions to C and that achieved very high
performance, good scaling and high energy efficiency by using compiler tricks
and some programmer annotations to let us exploit a fairly bare-bones parallel
system.
Last week’s S-REPLS
keynote by Sylvan
Clebsch was a talk
about the limitations of current microprocessor architecture and how it hides
everything of interest from the programmer: instruction level parallelism is
hidden behind out-of-order execution, message passing is hidden behind cache
coherency, etc. This reminded me that I have been meaning to write about the
SoC-C project that aimed to make parallelism
explicit by adding some language extensions to C and that achieved very high
performance, good scaling and high energy efficiency by using compiler tricks
and some programmer annotations to let us exploit a fairly bare-bones parallel
system.
The Ardbeg Software Defined Radio Project
SoC-C was one part of a larger project to develop an LTE software defined radio that could be used in a 4G mobile phone or wireless baseband station. I think Ardbeg had 50 people working on it at it’s peak and it consisted of 5 strands:
- Design a really really fast, really really energy-efficient digital signal processor (DSP) that can do all the hard work. The DSP was described in this paper.
- Figure out how to program the DSP without tearing your hair out.
- Design a radio sub-system containing multiple DSP engines each with their own private instruction and data memory, add some DMA engines to copy data and code from one engine to another and send/receive data from the digital frontend, add some specialized units to do error correction and add a control processor to drive the whole thing.
- Figure out how to program the radio sub-system without tearing your hair out. This was described in this paper.
- Read a stack of LTE protocol specifications and figure out how to implement the LTE physical layer efficiently.
All this had to fit into the power and area budget of existing custom ASIC solutions so instead of just building the hardware and then letting the software folks figure out how to use it, this was a giant co-design exercise: if the software needed a particular instruction, the hardware folk would look at how to add it; if the hardware folk said that some instruction was too power/area hungry, the software folk would see whether they could survive without it. There was a lot of arguing.
I was lucky enough to be one of the first few people on the project when we were making the initial design decisions and before we had split into separate teams. So I worked on parts of the vector instruction set supported by the DSPs, I worked on the programming model for the DSPs, I wrote some of the first few “kernels” for the DSPs, I built the system simulator. But mostly, I worked on the programming model for the whole subsystem.
I also came up with the name “Ardbeg” based on the idea that when the team went to the pub we would be sure to get in a round of my favourite whisky. Unfortunately, I had not noticed that none of the Cambridge pubs stocked “Ardbeg” so this was a lot less successful than I had planned. However, the idea caught on and for the next few years almost every research project at Arm was named after a whisky (or whiskey in our US office).
Building an Energy Efficient System
There is no real secret to building energy efficient, high performance hardware. You keep the clock rate low, use massive amounts of parallelism to compensate, split the memory into many small parts scattered across the system, avoid any unnecessary communication such as cache snooping and avoid all forms of speculation. General purpose CPUs generally don’t do this: they emphasize single-thread performance over energy efficiency because most software has not been parallelized. (Actually, I lie. There are a lot of secrets to low energy design. Most engineers pick them up slowly over a decade or so of working on low energy designs. For example, by working at Arm.)
The system we came up with looked a bit like this diagram (taken from this paper).
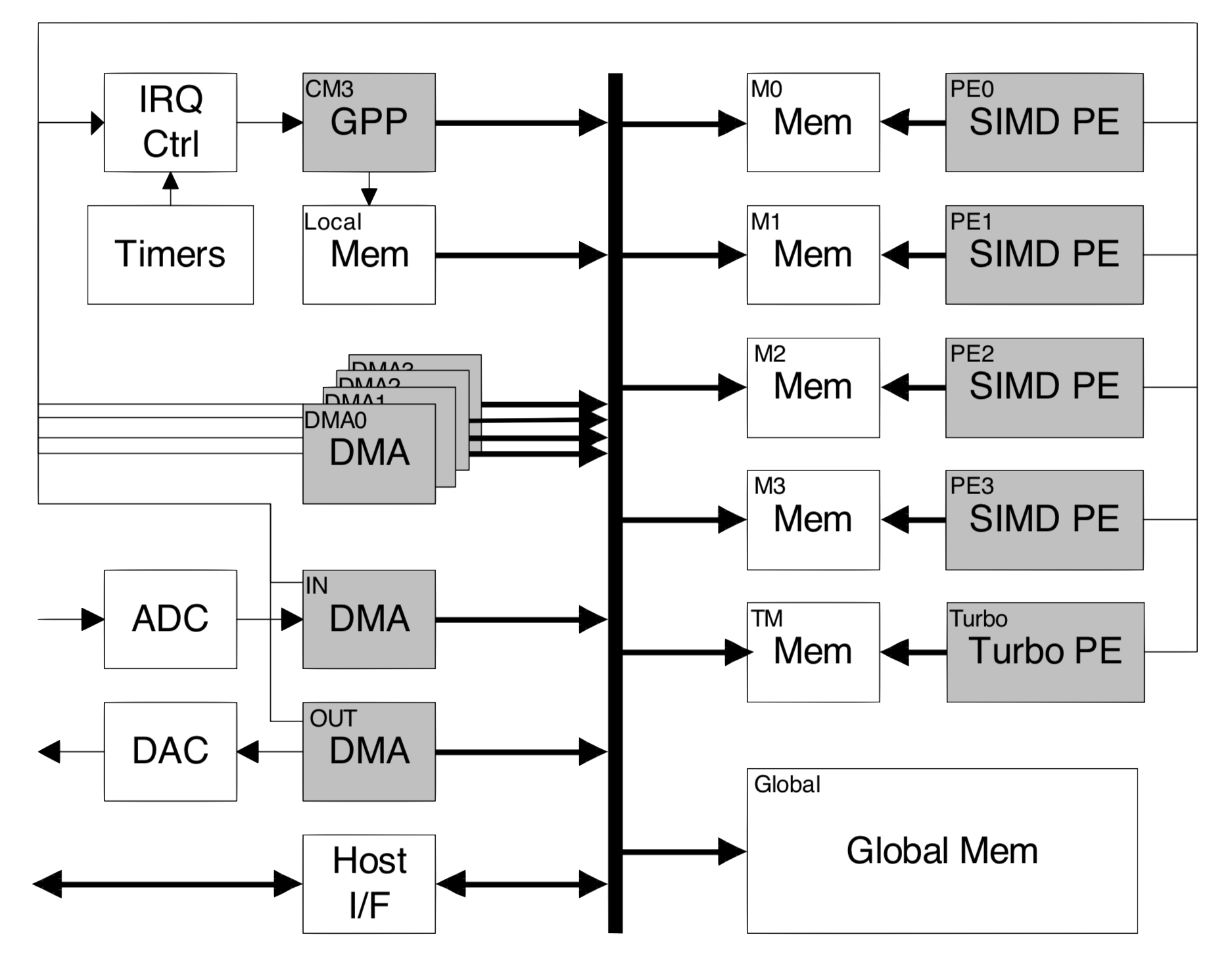
This shows a control processor (GPP) in the top left, the SIMD DSP engines on the right, everything has its own memory (in fact, everything typically had 2 memories: an instruction memory and a data memory). And, since we don’t have cache coherence to “automatically” move data from one processor’s memory to the next, we have to explicitly copy data between memories. Just the task of running a program on one of the DSP engines consisted of copying code into the instruction memory, copying constant tables into the data memory, copying the inputs into the data memory, telling the DSP what instruction to start at, waiting for the DSP to send an interrupt indicating that the program had finished and then copying the result from the data memory to whichever processor will use it next. To handle all this copying, there are a lot of DMA engines.
Programming the Radio Subsystem
The job of the control processor is to run tasks in the appropriate order and with as much parallelism as possible. The whole system is interrupt driven so the processor is constantly receiving interrupts signalling completion of one task (or a timer or …) in response to which it would start DSP tasks and DMA transfers. This is not an easy task. Worse, if you wanted to try mapping tasks to DSPs in a different way or if the hardware changed then you would have to rip up the current choreography and start again. There’s a reason that modern general purpose, out-of-order processors work so hard to hide the parallelism from you!
What we needed was a simple programming model that let you program at a high level but provide some hints about how you wanted the program to run. What I came up with was an extension of C that added
- compiler managed distributed shared memory
- remote procedure calls
- pipeline parallelism and fork-join parallelism
And, to keep the annotation burden low, I added annotation inference: using the annotations you had already added to infer additional annotations. This worked really well because there were so many private memories so once you had picked which processor was processing some data, there was no choice about which memory that data had to live in.
Compiler managed distributed shared memory
Distributed Shared Memory makes a fragmented memory behave like a shared memory by arranging to copy data from one processor’s memory to another whenever the other processor needs it. These decisions are usually made on demand at runtime: a processor checks whether the data is in its local memory and sends a request to obtain a copy if not (just like a cache). But those tests add overhead and fetching data on demand adds latency so, instead, I required the programmer to indicate when they want to synchronize one copy with another and used static analysis to figure out whether there were any missing syncs and used annotation inference to figure out which copies to perform.
Here is how we define where variables are to be placed in memory:
complex_t samples[2048] @ {GlobalMem, DMem1, DMem2};
complex_t freqs[2048] @ {DMem2};
byte_t FIR_code[] @ {GlobalMem, IMem1};
byte_t FFT_code[] @ {GlobalMem, IMem2};
byte_t FFT_twiddles[] @ {GlobalMem, DMem2};
This declares four variables “samples,” “freqs,” “FIR_code” and “FFT_code” and says that copies of them can be placed in both the global memory and in “DMem1,” “DMem2,” “IMem1” and “IMem2” (which are the private data and instruction memories of “DSP1” and “DSP2.” The “FIR_code” and “FFT_code” variables will hold the binary code for the FIR and FFT functions and “FFT_twiddles” will hold a table of constants used by the FFT function.
And here is some of the code from the SDR receiver. Notice that we reuse the “@” annotations to specify where each function should run. This is basically a remote procedure call invocation.
SYNC(FIR_code) @ DMA1; // copy code for FIR filter into DSP engine
SYNC(FFT_code) @ DMA1; // copy code for FFT into DSP engine
SYNC(FFT_twiddles) @ DMA1; // copy FFT data tables into DSP engine
...
while(1) {
ADC_get(&adc, &samples, 2048); // read 2048 samples from ADC
SYNC(samples) @ DMA1; // copy data into DSP engine
FIR(samples) @ DSP1; // Apply FIR filter to samples
SYNC(samples) @ DMA3; // copy samples from DMem1 to DMem2
FFT(freqs, samples) @ DSP2; // Apply FFT to samples, writing to freqs
...
}
This snippet shows us copying the code and constant tables from the global memory into the instruction memories of the DSP engines before we start. Then, inside the loop, we read data from the analogue-to-digital convertor (ADC), sync those samples (from the global memory to the DSP data memory), invoke the FIR function on the samples, sync the samples over to the data memory of the other DSP and invoke the FFT function on the second DSP.
In this case, I decided to run the FIR and the FFT tasks on separate processors. If I had decided to run them on the same processor, I would have had to copy the code for the two functions into the instruction memory by moving the SYNCs inside the loop. And, if I had forgotten to do that, then the compiler would have warned me that the ``FFT_code’’ copy in the instruction memory was incoherent with the copy in the global memory and needed to be reloaded.
The SoC-C compiler used the topology of the system to figure out that the ADC writes into GlobalMem and DSP1 can only read from DMem1 so it could figure out which direction to perform the DMA transfer although you can explicitly state what is to be synced with what if you want. In fact, half those annotations are redundant and can be omitted - I only put them in to help explain what is executing where and on what.
Looking back on it, I could have inserted the SYNC automatically in most cases but each copy was typically copying 4KB or 8KB of data and I wanted to be able to reason about the performance impact and to be able to assign it to a suitable DMA engine and parallelize it. (I am not sure whether making the SYNC explicit was a good decision - it didn’t make quite enough difference to be able to tell.)
Pipeline parallelism
SoC-C let you explicitly define parallel threads and provided the usual set of operations to communicate and synchronize between threads but it also provided annotations that could specify how you wanted the compiler to parallelize the code for you. Our DSP engines provided 512-bit wide vector operations so we did not need to express any more data parallelism but we did want to introduce pipeline parallelism. For example, in the above we might want a pipeline that is fetching data from the ADC at the same time as it is filtering the previous block of data at the same time as it is performing an FFT on the previous previous block of data.
The way you request pipeline parallelism in SoC-C is to introduce a FIFO to communicate between pipeline stages.
pipeline {
while(1) {
ADC_get(&adc, &samples, 2048);
FIFO(samples);
SYNC(samples) @ DMA1;
FIR(samples) @ DSP1;
SYNC(samples) @ DMA3;
FIFO(samples);
FFT(freqs, samples) @ DSP2;
...
}
}
In this example, I thought that performing the FIR calculation would take less time than the FFT calculation so I put the DMA transfers in the same thread as the FIR. If this turns out to be wrong, I can swap one of the SYNCs with the FIFO to fix it.
The SoC-C compiler would take this code, perform a dataflow analysis and realise that there were three independent pieces of code in this loop and then it would split it into three separate threads like this:
parallel_sections {
section {
while(1) {
ADC_get(&adc, &samples, 2048);
fifo_put(f1, samples);
}
}
section {
while(1) {
fifo_get(f1, samples);
SYNC(samples) @ DMA1;
FIR(samples) @ DSP1;
SYNC(samples) @ DMA3;
fifo_put(f2, samples);
}
}
section {
while(1) {
fifo_get(f2, samples);
FFT(freqs, samples) @ DSP2;
...
}
}
}
I am missing out some details about SYNC here - read the paper for a complete story. This version of the code (especially if I had shown you want happens with SYNC) is harder to read and is a pain in the ass to maintain.
From threads to interrupt handlers
But wait, didn’t I tell you that this all had to be implemented with efficient, low-latency interrupt handlers? So what am I doing introducing threads
- surely those are going to add a lot of overhead?
The trick to making all the above run efficiently is to convert the code into a bunch of state machines where each state corresponds to a point where a thread has to wait for a DSP, DMA engine, timer, ADC, etc. to finish before it can continue. Associated with each state, there will be an interrupt handling routine that clears the interrupt, performs a series of non-blocking actions to communicate between threads, start tasks, etc. and then, just before it finishes, it sets the interrupt handler for the next thing it has to wait for.
For example this thread
while(1) {
fifo_get(f1, samples);
SYNC(samples) @ DMA1;
FIR(samples) @ DSP1;
SYNC(samples) @ DMA3;
fifo_put(f2, samples);
}
performs four blocking actions (the first four lines) so it is transformed into a state machine with four states.
-
The action for the first state is triggered when data arrives from the previous stage of the pipeline. The action, starts the DMA transfer of samples from one memory to another, set the DMA1 interrupt handler to the action for the second state and return from the interrupt.
-
The action for the second state is triggered when DMA1 completes. It clears the interrupt, starts the FIR task on DSP1 and sets the DSP1 interrupt handler to the handler for the third state.
I will leave it to your imagination to fill in the details for the other two states, the other two receiver threads, the transmitter threads, other modes of operation (e.g., initially connecting with the base station), etc.
SoC-C manages tedious detail for the programmer
By now, you hopefully have a sense of how complicated the complete sequence of tasks in this system is. The complete stack had around 20-30 different tasks with DMA transfers between them and we were trying to make maximal use of our four DSPs, six DMA engines and Turbo accelerator. And we had to meet real-time requirements of processing the data quickly enough to meet protocol requirements and to keep up with the data transfer rate of 20M samples per second.
Doing this by hand would be horrendously complicated. I could imagine implementing this once or twice without SoC-C by drawing out all the state machines by hand, carefully reasoning about all the data copies between machines, etc. But I could not imagine trying lots of different mappings onto the different processors - it would just be too much work. So my mapping would probably end up in some local optimum but it would be too much work to try many different mappings in the hope of finding the global optimum. And I would regard changes to the system hardware with dread.
The idea of SoC-C was to eliminate most of the tedious, error-prone details from the task of mapping an algorithm onto the hardware. The programmer was still able/required to make the key decisions about the mapping but then SoC-C filled in and expanded out all of the details.
Conclusion
This post was inspired by Sylvan Clebsch’s talk about how modern out-of-order microprocessors were hiding too much of the hardware’s raw parallel potential from the programmer. I see SoC-C is one datapoint in an alternative design space where the programmer can directly access that parallelism.
SoC-C was targetted at expert programmers who are willing to spend significant time getting a small number of very high value programs to run very efficiently on hardware custom designed to run those programs. The key idea was to let you add annotations to a portable program to customize it for some platform.
Another point on the design space would be where the compiler automatically decides how to map the program onto the hardware either based on heuristics or based on a number of trial mappings.
Yet another point on the design space would change the hardware to be better suited to general purpose workloads and use a JIT to decide how to map the program onto the hardware.
There are many, many points and still, after more than 50 years of research into parallel computing, I think very few of them have been explored. Or, to misquote Tolstoy,
All sequential processors are alike; each parallel system is parallel in its own way.
Related posts and papers
The opinions expressed are my own views and not my employer's.